文本信息提取
介绍
文本信息分为非结构化的及结构化的,非结构化的文本信息并不适合机器的理解,例如一整份简历、一大段判决书。但这种信息在经过文本结构化处理之后,可以形成让计算机更容易读取、理解和分析的结构化数据,从而辅助人类决策,产生数据价值。
输入
自然语言描述
输出
结构化信息
示例

AI+通用技术可以运用在各个行业领域解决不同问题
文本信息分为非结构化的及结构化的,非结构化的文本信息并不适合机器的理解,例如一整份简历、一大段判决书。但这种信息在经过文本结构化处理之后,可以形成让计算机更容易读取、理解和分析的结构化数据,从而辅助人类决策,产生数据价值。
自然语言描述
结构化信息
文本分类是对一段描述性的文本进行特征提取,语义理解及建模,最终判断所属类别的技术。例如根据一段工作描述判断职能名称,根据一段案情描述判断案件类型,或根据一段建筑描述判断建筑类型。
一段文本
类别信息

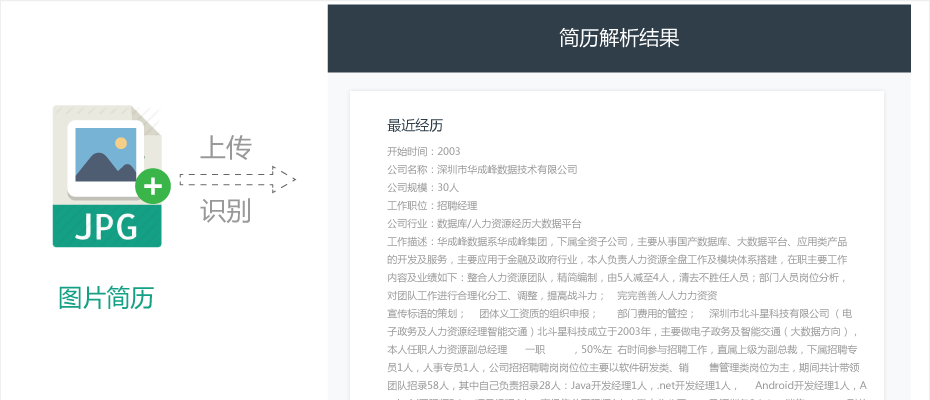
图像信息提取,即利用OCR (Optical Character Recognition)技术将印刷字符转化为图像文字后再转换为文本格式,以便计算机直接处理和加工文本信息。可提取的对象包括图片简历、图片名片和图片列表等。
带有文字的图片
文本信息
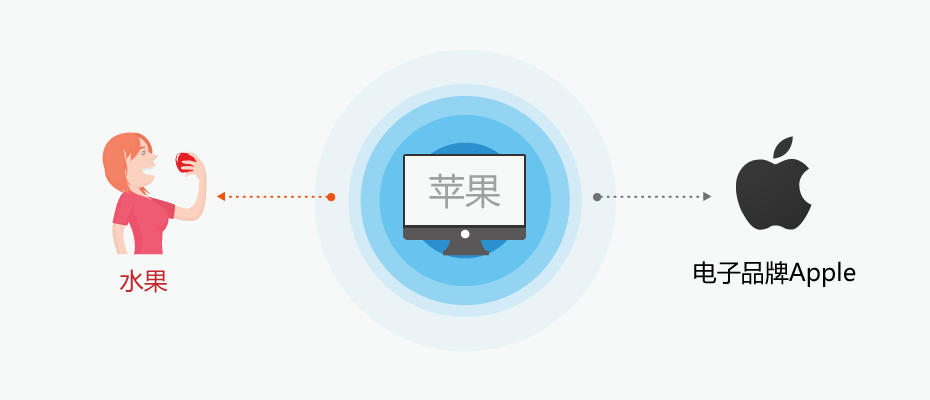
语义理解是指计算机能够像人一样理解语句背后的意思,即词语和句子在语境中的意思,例如“苹果”在某些语境下是水果,另外一些语境下是著名的苹果公司。另外语义理解还能让计算机进行联想,明白语句背后的内容,例如“招聘有互联网大公司经验的UX设计师”,语义理解技术能够理解互联网的大公司有哪些,UX设计师实际也包括交互设计师、UE设计师等。这是关键词句匹配没有办法达到的认知水平。
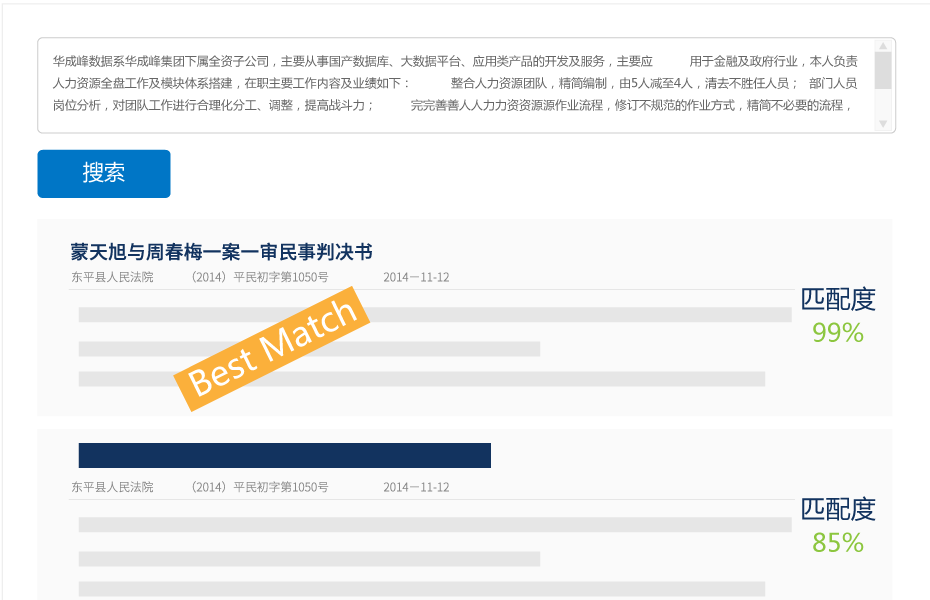
自然语言文档检索能够在一定的训练模型下,针对输入的语句寻找到相关的文本信息,并对结果进行相关度排序。
应用的场景示例:
-
根据招聘要求推荐最适合的候选人简历
- 根据求职者的简历推荐最适合的工作机会
-
根据案情的描述找到最相似的案例、判决书和法条
- 根据案情的描述推荐最适合处理该案的律师